Introduction to NFL Analytics with R
Bradley J. Congelio 

Welcome to the online home of Introduction to NFL Analytics with R, which was published with CRC Press (in the Data Science Series) in December 2023. It is avaliable for purchase in both paperback and hardback on both Amazon and the Routledge website (as well as numerous other outlets).
If you wish to further support the development of this book, please consider one of the following:
Submitting an issue or making a pull request at the book’s official GitHub repository.
Buy me a coffee to help me fuel up for the ongoing edits and updates to the book.
Early praise for Introduction to NFL Analytics with R:
This is the best resource an aspiring data scientist looking to work with football data can use. It has something for all levels, including data analysis, visualization, advanced modeling, and more. The code and the insights in Introduction to NFL Analytics with R are invaluable and can help everyone from beginners to those who have worked with data for years. - Tej Seth, Data Scientist (SumerSports)
As someone with a non-traditional path into data science, I’ll often read tutorials on fundamentals of DS/ML and still learn something new. That said, Brad Congelio’s NFL Analytics with R book is great for those trying to get into coding and ML in sport. - Sam Hoppen, Data Scientist (Fantasy Pros)
Social media reactions to Introduction to NFL Analytics with R:
Acknowledgements
Ultimately, this book would not have been possible if not for Rob Calver, a Senior Publisher with Chapman & Hall/CRC, instantly believing in the slightly disjointed vision and idea of a random person (me!) e-mailing him out of the blue back in June of 2022. His guidance during the process of writing, receiving reviews, editing, and moving the book into production has been phenomenal. The same can be said for Sherry Thomas, a Senior Editorial Assistant, who assisted in getting the book prepared for production.
Several members of the nflverse family also played a significant role in the creation of this book. First and foremost is Ben Baldwin, who provided the necessary “this book is a great idea, you should do it!” push to get me started on the project. Moreover, the nflverse family of packages are obviously a major part of this project and, without them, the end result would not be nearly as robust. Ben, along with Tan Ho and Sebastian Carl, have done more for the NFL analytics movement than they are ever willing to admit. This book is a testament to their hard work, vision, and ability. As well, many members of the nflverse Discord graciously took the time to submit issues to the book’s repository highlighting issues in both spelling/grammar and coding/data. Because of this, I’ll argue that Introduction to NFL Analytics with R was created, in part, in the same open-source vision as the nflverse and, more broadly, the R programming language.
The football illustration on the cover of the book was created by Corinne Deichmeister, a Spring 2023 graduate of Kutztown University’s Communication Design program. In the same vein, Dr. Anne Carroll - the Dean of the College of Business at Kutztown University of Pennsylvania - provided financial assistance above and beyond what I had in my professional development account to fund the creation of the book’s illustration.
Preface
On April 27, 2020, Ben Baldwin hit send on a Tweet that announced the birth of nflfastR, an R package designed to scrape NFL play-by-play data, allowing the end-user to access it at speeds quicker than similar predecessors (hence the name).
Thanks to the work of multiple people (@mrcaseB, @benbbaldwin, @TanHo, @LeeSharpeNFL, and @thomas_mock … to name just a few), the process of getting started with analytics using NFL data is now easier than ever.
That said, and without getting too far into the weeds of the history, the above-mentioned people are responsible in some shape or form for the current status of the nflverse, which is a superb collection of data and R-based packages that allows anybody the ability to access deeply robust NFL data as far back as the 1999 season.
The nflverse as we know it today was initially birthed from the nflscrapR project, which was started by the Carnegie Mellon University student and professor duo of Maksim Horowitz and Sam Ventura. After Horowitz graduated - and got hired by the Atlanta Hawks - the nflscrapR package was taken over by fellow CMU student Ron Yurko (who would go on to receive his Ph.D. from the Statistics and Data Science program and, at the time of this book’s writing, is an Assistant Teaching Professor in the Department of Statistics and Data Science at CMU). The trio’s work on nflscrapR led to a peer-reviewed paper titled “nflWAR: A Reproducible Method for Offensive Player Evaluation in Football.” Ultimately, the nflscrapR project came to an end when the specific .json feed used to gather NFL data changed. At this point, Ben Baldwin and Sebastian Carl had already built upon the nflscrapR project’s foundations to create nflfastR. Yurko officially marked the end of the nflscrapR era and the beginning of the nflfastR era with a tweet on September 14, 2020:1
As a reply to his first tweet about the nflfastR project, Baldwin explained that he created the original function to scrape NFL data for the creation of his NFL analytics website. Thankfully, he and Carl did not keep the creation to themselves and released nflfastR to the public. Because of the “open source” nature of R and R packages, a laundry list of companion packages quickly developed alongside nflfastR. The original nflfastR package is now part of the larger nflverse of packages that drive the NFL analytics community on Twitter and beyond.
The creation of the nflverse allowed for anybody interested in NFL analytics to easily access data, manipulate it to their liking, and release their visualizations and/or metrics to the wider public. In fact, it is now a regular occurrence for somebody to advance their R programming ability because of the nflverse and then go on to win the Big Data Bowl. As of the 2022 version of the Big Data Bowl, over “30 participants have been hired to work in data and analytics roles in sports, including 22 that were hired in football” (Big Data Bowl, n.d.). Most recently, the Chargers hired 2020 participate Alex Stern and the Chiefs hired Marc Richards, a member of the winning 2021 team, as a Football Research Analyst.
Kevin Clark, in a 2018 article for The Ringer, explained that despite not being as obvious as the sabermetrics movement in baseball, the analytics movement in the NFL is “happening in front of you all the time.” The use of analytics in the NFL did, however, predate Clark’s article. In 2014, Eagles head coach Doug Pederson explained that all decisions made by the organization - from game planning to draft strategy - are informed by hard data and analytics. Leading this early adoption of analytics, and reporting directly to team Vice President Howie Roseman, were Joe Douglas and Alec Halaby, “a 31-year-old Harvard grad with a job description” that had an emphasis on “integrating traditional and analytical methods in football decision-making.” The result? A “blending of old-school scouting and newer approaches” that were often only seen in other leagues, such as the NBA and MLB (Rosenthal, 2018). Pederson believed in and trusted the team’s approach to analytics so much that a direct line of communication was created between the two during games, with the analytics department providing the head coach with math-based recommendations for any scenario Pederson requested (Awbrey, 2020).2
In just under five years time since the publishing of that article, it has become hard to ignore the analytic movement within the NFL. Yet, there is still so much growth to happen in the marriage between the NFL and advanced metrics. For example, there is no denying that the sabermetrics movement drastically “altered baseball’s DNA” Heifetz (2019)]. Moreover, as explained in Seth Partnow’s outstanding The Midrange Theory: Basketball’s Evolution in the Age of Analytics, the analytics movement in the NBA essentially killed the midrange shot (briefly: it is more beneficial to try to work the ball in directly under the basket (for a high-percentage shot) or to take the 3-pointer, as the possible additional point is statistically worth more despite the lower success probability as opposed a 2-point midrange shot).
Compared to both the NBA and MLB, the NFL is playing catch up in analytics driving changes equivalent to the death of the midrange shot or the plethora of additional tactics and changes to baseball because of sabermetrics. Joe Banner, who served as the President of the Eagles from 2001-2012 and then the Chief Executive Officer of the Browns from 2012-2013, explained that some of the hesitation to incorporate analytics into NFL game planning was a result of the game being “very much driven by conventional wisdom to an extreme degree” (Fortier, 2020). Perhaps nobody encapsulates this better than Pittsburgh SteelersHead Coach Mike Tomlin. When asked about his position on analytics during the 2015 season, Tomlin explained:
I think that’s why you play the game. You can take analytics to baseball and things like that but football is always going to be football. I got a lot of respect for analytics and numbers, but I’m not going to make judgements based on those numbers. The game is the game. It’s an emotional one played by emotional and driven men. That’s an element of the game you can’t measure. Often times decisions such as that weigh heavily into the equation (Kozora, 2015).
Given that Tomlin’s quote is from 2015, perhaps the Steelers pivoted since and are now more analytically inclined. That does not seem to be the case. In a poll of NFL analytics staffers conducted by ESPN, the Steelers were voted as one of the least analytically advanced teams in the league.
There is large gap between the least analytically inclined teams (Washington, Tennessee, Cincinnati, New York Giants, and Pittsburgh) and those voted as the most analytically inclined (Baltimore, Cleveland, Philadelphia, and Houston). In the ESPN poll, the Browns were voted as the analytics department producing the highest level of work. One of those polled spoke to the fact that much of this outstanding work is a result of General Manager Andrew Berry being a “true believer,” explaining that he is one of the “rare guys you’ll come across in life where you think to yourself, ‘Man, this guy thinks at a different level. Just pure genius.’ He’s one of them.”
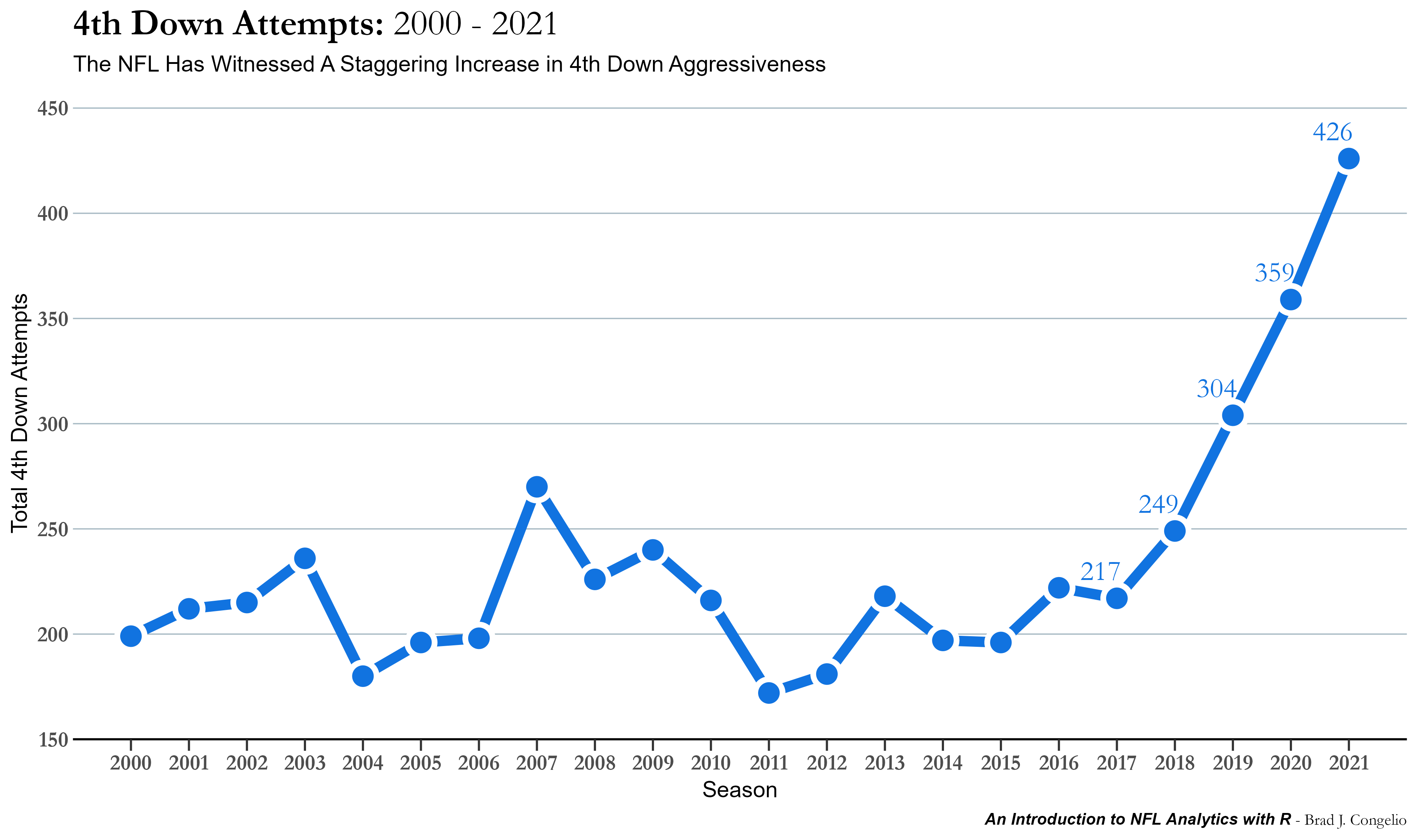
In his article for the Washington Post, Sam Fortier argues that many teams became inspired to more intimately introduce analytics into game planning and on-field decisions after the 2017 season. On their run to becoming Super Bowl Champions, the Philadelphia Eagles were aggressive on 4th down, going for it 26 times during the season and converting on 17 of those for a conversion percentage of 65.4%. An examination and visualization of the data highlights the absolutely staggering increase in 4th down aggressiveness among NFL head coaches from 2000-2021:
There has been a 96.3% increase in the number of 4th down attempts from just 2000 to 2021. In fact, the numbers may actually be higher as I was quite conservative in building the above plot by only considering those 4th down attempts that took place when the offensive team had between a 5-to-95% winning probability and those prior to the two-minute warning of either half. Even with those conservative limitations, the increase is staggering. The numbers, however, support this aggression. During week one of both the 2020 and 2021 seasons, not going for it on 4th down “cost teams a cumulative 170 percentage points of win probability” (Bushnell, 2021).
Ben Baldwin, using the nfl4th package that is part of the nflverse, tracked this shift in NFL coaching mentality regarding 4th down decisions by comparing 2014’s “go for it percentage” against the same for 2020. When compared to the 2014 season, NFL coaches are now much more in agreement with analytics on when to “go for it” on 4th down in relation to the expected gain in win probability.
It should not be surprising then, considering Mike Tomlin’s quote from above and other NFL analytics staffers voting the Steelers as one of the least analytically driven teams in the league, that Pittsburgh lost the most win probability by either kicking or punting in “go for it” situations during the 2020 NFL season. On the other end, the Ravens and Browns - two teams voted as the most analytically inclined - are the two best organizations at knowing when to “go for it” on 4th down based on win probability added. There seems to be a defined relationship between teams buying into analytics and those who do not:
The NFL’s turn towards more aggressive 4th-down decisions is just one of the many analytics-driven changes occurring in the league. Another significant example is Defense-Adjusted Value over Average (or DVOA), a formula created by Aaron Schatz, now the editor in chief of Football Outsiders, that sought to challenge the notion that teams should, first, establish the running game in order to open up the passing game. Some of these changes are apparent on televisions screens on Sunday afternoons in the Fall, while others are occurring behind the scenes (analytics departments working on scouting and draft preparation, for example). Indeed, the use of analytics in the NFL is not as tightly ingrained as we see in other prominent leagues. And we must remember that there are certainly continued hold outs among some NFL coaches (like Mike Tomlin).
Despite some coaching hold outs on fully embracing analytics, the “thirst for knowledge in football is as excessive as any other sport and the desire to get the most wins per dollar is just as high.” As the pipeline of data continues to grow, both internally in the league and data that becomes publicly accessible, “smart teams will continue to leave no rock unturned as they push the limits on how far data can take them.” Joe Banner explained that while the NFL has long been a league of coaches saying “well, that is the way we’ve always done it,” the league is ripe for a major shift (Bechtold, 2021).
Banner’s belief that those teams searching for every competitive advantage will “leave no rock unturned” is the driving force behind this book. For all intents and purposes, the age of analytics in the NFL is still in its infancy. Turning back, again, to the 2017 season, the Eagles’ management praised and credited the team’s analytics department as part of the reason they were able to win Super Bowl LII. Doing so, Danny Heifetz argues, “changed the language of football.” The NFL, he explains, is a “copycat league” and, as witnessed with the increase in 4th down aggressiveness since 2017, teams immediately began to carbon copy Philadelphia’s approach to folding traditional football strategy with a new age analytics approach. Because of the modernity of this relationship between long-held football dogmas and analytics, nobody can be quite sure what other impacts it will create on the gamesmanship of football.
However, as Heifetz opines, both the NBA and MLB can serve as a roadmap to where analytics will take the NFL. Importantly, the NFL’s relationship with analytics is still in its “first frontier of what will likely be a sweeping change over the next two decades.” Because of this, we cannot be sure what the next major impact analytics will make, nor when it may occur. But, with the ever-growing amount of publicly accessible data, it is only a matter of time until it is discovered. For example, in an interview with Heifetz, Brian Burke - one of the forefather’s of NFL analytics and now a writer for ESPN - expressed his belief that the next major impact will be “quantifying how often quarterbacks make the correct decision on the field.”
It seems that every new NFL season results in an amateur analyst bringing a groundbreaking model and/or approach to the table. Unlike, for example, MLB where there is little left to discover in terms of sabermetrics and new approaches to understanding the game and its associated strategy, the NFL is - for lack of a better phrase - an open playing field. With more and more data becoming available to the public, it is now easier than ever investigate your own ideas and suspicions and to create your own models to confirm your intuition.
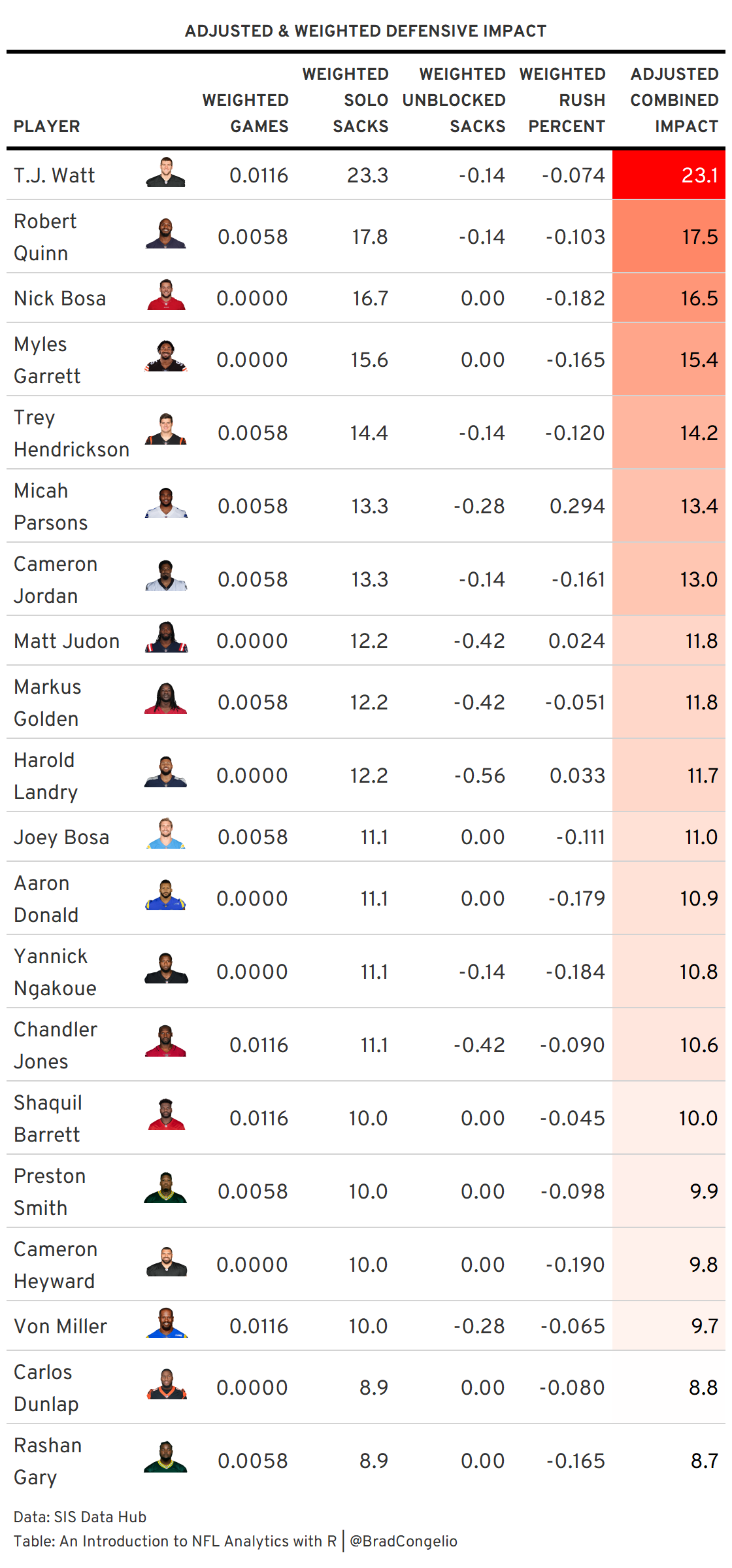
For example, I am originally from the greater Pittsburgh area and am a big Steelers fan (which certainly explains some of the Steelers-centric examples I use in the writing of this book). I was adamant in my belief that Pittsburgh’s TJ Watt should win the 2021 Defensive Player of the Year award, despite many others calling for Los Angeles’ Aaron Donald to claim the title. In effort to prove my point, I sought out to design what I coined Adjusted Defensive Impact. To begin, I wanted to explore the idea that not all defensive sacks are created equal, as a player’s true impact is not always perfectly represented by top-level statistics.
To account for that, I opted to adjust and add statistical weight to sack statistics. This was done over multiple areas. For instance, not all players competed in all 17 regular-season games in 2021. To adjust for this, I took the total of game played in the data (2,936) and divided by 17 (a full season) to achieve a weighted adjustment of 0.0058. TJ Watt played in just 15 games in 2021. His adjusted equation, therefore, is (17-‘games’) * 0.0058. The result? He gets a bit more credit for this adjustment than, say, Myles Garrett who played all 17 regular-season games.
Going further with the model, I created a weighted adjustment for solo sacks (0.90), a negative weighted adjustment (-0.14) for any sack charted as “unblocked,” and a weighted adjustment to account for how many times a player actually rushed the QB compared to how many defensive snaps they played. Using data from the SIS Data Hub, the full code is below:
options(digits = 2)
pass.data <- pass_rush_data %>%
select(Player, Team, Games, `Pass Snaps`, `Pass Rushes`,
`Solo Sacks`, `Ast. Sacks`, `Comb. Sacks`,
`Unblocked Sacks`, Hurries, Hits) %>%
rename(total.snaps = `Pass Snaps`,
total.rushes = `Pass Rushes`,
solo.sacks = `Solo Sacks`,
asst.sacks = `Ast. Sacks`,
comb.sacks = `Comb. Sacks`,
unblocked.sacks = `Unblocked Sacks`,
player = Player,
team = Team,
games = Games,
hurries = Hurries,
hits = Hits)
pass.data$rush.percent <- pass.data$total.rushes / pass.data$total.snaps
calculated.impact <- pass.data %>%
group_by(player) %>%
summarize(
adjusted.games = (17 - games) * 0.0058,
adjusted.solo = solo.sacks * 0.9,
adjusted.unblocked = unblocked.sacks / -0.14,
adjusted.rush.percent = 0.81 - rush.percent,
combined.impact = sum(adjusted.games +
(solo.sacks * 0.9) +
(unblocked.sacks * -0.14) +
adjusted.rush.percent))The end result? Taking into account the above adjusted defensive impact, TJ Watt was absolutely dominant during the 2021 season:
All of these examples - from Ben Baldwin’s 4th-down model, to Football Outsiders’ DVOA, to my attempt to further quantify defensive player impact - are just the leading edge of the burgeoning analytics movement in the NFL. Moreover, the beauty of analytics is that you do not have to be a mathematician or statistics buff in order to enter the fray. All it takes is a genuine curiosity to explore what Bob Carroll, Pete Palmer, and John Thorn coined as the “Hidden Game of Football” and the desire to learn, if you have not already, the R programming language.
Who This Book Is For
Writing a book that is wholly dependent on the R programming language to achieve the end goals is not an easy task, as there are likely two types of people reading this: those with familiarity in R and those without. If you are part of the former group, you can likely skip chapter 2 as it is a primer on installing R and learning the language of the tidyverse. On the other hand, if you are part of the latter group, you should skip ahead to chapter 2 before even looking at chapter 1, which serves as an introduction to NFL analytics with examples. That said, this book can serve multiple audiences:
Those interested in learning how to produce NFL analytics regardless of their current knowledge of the R programming language.
Professors who instruct data science courses can provide lessons through the lens of sport or, perhaps better, create their own Sport Analytics courses designed around the book. Moreover, future plans for this book include instruction reference guides to include PowerPoint templates, assignments/project instructions and grading rubrics, and quiz/exam content for online management systems (D2L, Canvas, Moodle, etc.).
Students are able to use this book in multiple ways. For example, in my Sport Analytics course, students are first introduced to R and the
tidyverseusing the built-in R data sets (mtcars,iris, andnycflights13). While those data sets certainly serve a purpose, I have found that students grasp the concepts and language of thetidyversemore quickly when the class turns to using data from thenflverse. Because of this, students can use this book to start learning the R programming language using football terms (passing yards, first downs, air yards, completion percentage over expected) as opposed to the variables they may find much less interesting housed in the built-in data. Moreover, students already fluid in R can use this book to construct machine learning models using football data, for example, as part of assignments in data science/analytics courses.Journalists, bloggers, and arm-chair quarterbacks alike can use the book to underpin their arguments and to provide hard data to backup their claims.
It is also important to note that it is not expected for you to be an expert in statistics, coding, or data modeling in order to find this book useful. In fact, I self-taught myself the R programming language after discovering its potential usefulness in my personal academic research. I only “became more serious” about advancing my understanding of the language’s nuances, and more advanced methods, after discovering the nflscrapR package and using it as my learning tool for the deep dive into R. My decision to pursue an academic certificate in the language was driven by the creation of my Sport Analytics course, as the certificate provided the proof of “academic training” that was necessary to move the course through the University’s curriculum committee. Nonetheless, because of this self-taught journey - and despite being an academic myself - I find that I largely avoid the use of “complicated jargon” that is so evident in most formal writing. A core goal of this book was to write it in an accessible format, providing the information and step-by-step instructions in a more informal format than readers of similar books may be accustomed to. Learning a coding language can be difficult enough, so I do not see the need for readers to also decipher overly-complicated prose. This book is not written from atop the ivory tower, and for that I will not apologize.
Because of this, and regardless of which chapter you begin with, I believe that this book achieves its main goal: to provide a gentle introduction to doing NFL analytics with R.
As this book is published online, it allows me to continue real-time development of it, so please make note of the following:
Introduction to NFL Analytics with R is published through CRC Press.
Please feel free to contribute to the book by filing an issue or making a pull request at the book’s GitHub repository: Introduction to NFL Analytics with R Github Repository
The majority of the chapters conclude with exercises. In some cases, prepared data will be provided with a link to download the file. In other cases, you are expected to use the
nflverseto collect the data yourself. In either case, the answers to the exercises are include in the book’s Git repository: Answers to Chapter Exercises.Soon there will be a YouTube series to go along with the written version of this book. In brief, the videos will include my going over each chapter, step-by-step, with additional instruction and/or approaches.
Are you an instructor hoping to create or grow your Sport Analytics course? Future plans for this book include the creation of Instructor Materials to include an example syllabus plus structured lesson plans, exercises, assignments, quizzes, and exams. As well, templates for lectures will be included in PowerPoint form so you may edit to fit your specific needs.
Overview of Chapters
Chapter 1 introduces the process of investigate inquiry, and how it can be used to formulate a question to be answered through the use of data and R. Specifically, the chapter provides a broad overview of what is possible with analytics and NFL data by exploring the impact of having a high number of unique offensive line combinations had on the 2022 Los Angeles Rams. The process of data collection, manipulation, preparation, and visualization are introduced to seek the answer regarding how changes in an offensive line can impact various attributes of an offense. The chapter concludes with another working example, allowing readers to explore which teams from the 2022 season most required an explosive play per drive to score a touchdown.
Chapter 2 covers the process of downloading both R and RStudio, as well as the necessary packages to do NFL analytics. As one of the most important chapters in the book (especially for those new to the R programming language), readers take a deep dive into wrangling NFL data with the
tidyversepackage. To begin, readers will learn about thedplyrpipe (%>%) and use, in exercises, the six most important verbs in thedplyrlanguage:filter(),select(),arrange(),summarize(),mutate(), andgroup_by(). At the conclusion of the chapter, multiple exercises are provided to allow readers to practice using thedplyrverbs, relational operators within thefilter()function and creating “new stats” by using thesummarize()function. Moreover, readers will determine the relationship between thedplyrlanguage and important variables within thenflversedata such asplayer_nameandplayer_id, which is important for correct manipulation and cleaning of data.Chapter 3 examines the numerous and, often, bewildering amount of functions “underneath the hood” of the packages that makes up the
nflverse. For example,load_pbp()andload_player_stats()are included in bothnflfastRandnflreadr. However,load_nextgen_stats(),load_pfr_stats(), andload_contracts()are all part of justnflreadr. Because of this complexity, readers will learn how to efficiently operate within thenflverse. Moreover, chapter 3 provides a plethora of examples and exercises related to all of the various functions included.Chapter 4 moves readers from data cleaning and manipulation to an introduction to data visualization using
ggplot2. As well, chapter 4 provides further instruction onnflversefunctions such asclean_player_names(),clean_team_abbrs(), andclean_homeaway(). As well, to prep for data visualization, readers will be introduced to theteams_colors_logosandload_rostersfunctions as well as thenflplotRpackage, which provides “functions and geoms to help visualization of NFL related analysis” (Carl, 2022). Readers will produce multiple types of visualizations, includinggeom_bar,geom_point,geom_density, and more. As well, readers will learn to usefacet_wrapandfacet_gridto display data over multiple seasons. For visualizations that include team logos or player headshots, instruction will cover both how to do the coding manually usingteams_colors_logosorload_rostersand to use thenflplotrpackage to avoid the need to useleft_jointo mergeteams_colors_logosto your data frame. At the conclusion of the chapter, readers will be introduced to thegtandgtExtraspackages for creating sleek tables as well as be walked through the creation of their first Shiny App.Chapter 5 introduces advanced methods in R using
nflversedata, with a specific focus on modeling and machine learning. To streamline the process of learning, readers will be introduced totidymodels, a “collection of packages for modeling and machine learning usingtidyverseprinciples” (Silge, n.d.). Readers will first be introduced to the modeling process by creating and running a simple linear regression model. After, regressions are built upon with multiple linear regressions, binary regressions, and binomial regression. Readers will then begin working with more advanced methods of machine learning, such as k-means clustering and building an XGBoost model.
Technical Details
This book was written using RStudio’s Visual Editor for R Markdown. It was published using the Quarto publishing system built on Pandoc. As well, the following packages were used in this book:
| package | version | source |
|---|---|---|
| arrow | 10.0.1 | CRAN (R 4.1.3) |
| bonsai | 0.2.1 | CRAN (R 4.1.3) |
| caret | 6.0-94 | CRAN (R 4.1.3) |
| cowplot | 1.1.1 | CRAN (R 4.1.1) |
| cropcircles | 0.2.1 | CRAN (R 4.1.3) |
| doParallel | 1.0.17 | CRAN (R 4.1.3) |
| dplyr | 1.1.1 | CRAN (R 4.1.3) |
| extrafont | 0.19 | CRAN (R 4.1.3) |
| factoextra | 1.0.7 | CRAN (R 4.1.1) |
| geomtextpath | 0.1.1 | CRAN (R 4.1.3) |
| ggcorrplot | 0.1.4 | CRAN (R 4.1.3) |
| ggfx | 1.0.1 | CRAN (R 4.1.3) |
| ggimage | 0.3.1 | CRAN (R 4.1.3) |
| ggplot2 | 3.4.2 | CRAN (R 4.1.3) |
| ggpmisc | 0.5.2 | CRAN (R 4.1.3) |
| ggrepel | 0.9.2 | CRAN (R 4.1.3) |
| ggridges | 0.5.4 | CRAN (R 4.1.3) |
| ggtext | 0.1.2 | CRAN (R 4.1.3) |
| glue | 1.6.2 | CRAN (R 4.1.3) |
| gt | 0.8.0 | CRAN (R 4.1.3) |
| gtExtras | 0.4.5 | CRAN (R 4.1.3) |
| lightgbm | 3.3.5 | CRAN (R 4.1.3) |
| magick | 2.7.3 | CRAN (R 4.1.1) |
| nflfastR | 4.5.1 | CRAN (R 4.1.3) |
| nflreadr | 1.3.2 | CRAN (R 4.1.3) |
| nflverse | 1.0.2 | https://nflverse.r-universe.dev (R 4.1.3) |
| nnet | 7.3-16 | CRAN (R 4.1.1) |
| RColorBrewer | 1.1-3 | CRAN (R 4.1.3) |
| reshape2 | 1.4.4 | CRAN (R 4.1.1) |
| scales | 1.2.1 | CRAN (R 4.1.3) |
| tidymodels | 1.0.0 | CRAN (R 4.1.3) |
| tidyverse | 2.0.0 | CRAN (R 4.1.3) |
| vroom | 1.6.1 | CRAN (R 4.1.3) |
| webshot | 0.5.4 | CRAN (R 4.1.3) |
Finally, please note that this book uses the dplyr pipe operator (%>%) as opposed to the new, built-in pipe operator released with version 4.1 of R (|>). It is likely that you can work through the exercises and examples in this book by using either operator. I maintain my use of the dplyr pipe operator for no other reason than a personal (and problematic) dislike of change.
License
The online version of this book is published with the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International (CC BY-NC-ND 4.0) license.